What I usually pursue is the minimization of unintended change and optimization for readability, most of what we do with code is reading. The refactoring is guided towards patterns and SOLID.
These notes are taken with my environment in mind: A statically typed language, OOP, and dependency injection. Obviously, they do not cover everything. I put here some common smells or mistakes that I have seen recently.
Rules
No modification is allowed in production code that is not covered by tests. The rule can be bent when the change is made with automated refactorings that rely on the compiler and the type system. In this initial phase, the goal is to improve readability, gain understanding and enable testing.
Code hard to test usually involves actions that produce slow operations (call to database/network) or side effects in systems that we do not own. We will need to configure these actions so they operate as we want, to force different test cases. A seam is a place that allows us to alter how the program behaves without modifying what it does in that location. Removes the dependency and makes possible to specify a different implementation in our tests without modifying production code.
Typically and as a first step, this is implemented using the features of the language to manage visibility as the 'protected' keyword in Java or C#. Production code uses the original method, test code subclasses the class using an alternative version of the dependency.
The last step with dependencies, once the class is covered, would be to use inversion of control and inject them if possible using constructor injection.
Managing frustration
Covering legacy code or adding new features can be incredibly frustrating. Get an accurate idea of what the code does at once is hard. A nicer approach is start writing tests for the outer branches of the code and after, step by step, start covering the inner branches.
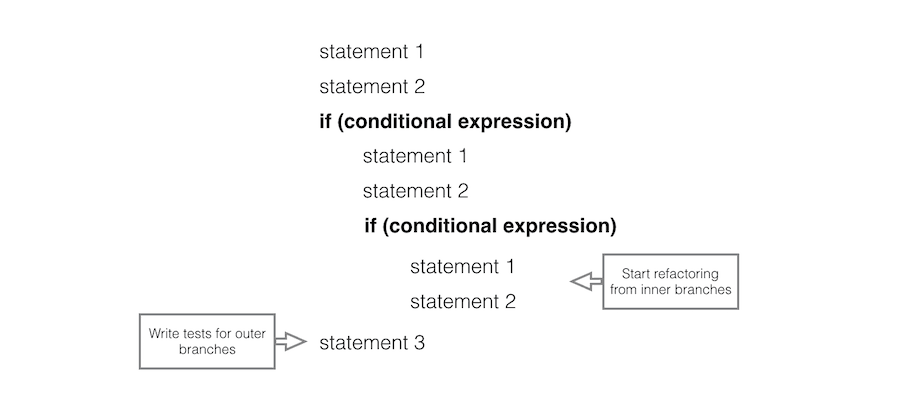
Outer branches are easier to understand as the state needed to execute them is smaller. That implies also that our setup code will be shorter putting ourselves in a position where it will be easier to see the first test passing. As we start to cover inner branches we already have an idea of the setup needed and we acquire knowledge incrementally, refactoring also our test codebase and reducing the cognitive load when tackling more complex scenarios.
Software to audit the test coverage can be very useful as it helps to visualize how we move from not covered to covered and from outer to inner branches.
Traits to remove
Hidden dependencies: Look for the ‘new’ keyword in the code. Instantiation of new objects usually means hidden, implicit dependencies. Behavior impossible to alter in our tests. Extract to protected method, subclass, and cover. After that, the dependency can be completely isolated creating a new abstraction for it and enabling dependency injection later if that is possible.
Single Responsibility: Classes, functions, should have just one reason to change. Let us imagine a class that calls to a server to get some data, parses the information returned to JSON and then manipulates some of the fields. What could make this abstraction change?:
-
The technology that we use to call the remote server is something that can change. Today we may be using HTTP and change in the future to a different technology. That process should be abstracted.
-
Today we parse from JSON, but in the future, the service could return something else. That parsing should be abstracted.
-
The manipulation of the fields could have a meaning by itself from the domain point of view. That logic should live in the object and encapsulate that behavior.
The input and return types should abstract completely the operation. No internal change in the abstractions should affect to the consumers, as the contract whereby they consume the results should not change.
Interface segregation (Martin): Inspect visually the constructor of the class, all its dependencies and the parameters of the methods/functions. As a consumer of these entities, is the class only seeing what it needs to see?. Keeps the system decoupled and easy to refactor.
Feature envy and anemic model: When an object accesses data of another object more than its own. It is quite usual to see this in classes that act as orchestrators or managers when they perform operations that should belong to the objects in the model. A symptom of an anemic domain model is logic leaking to these managers. Take a look at the methods and try to identify operations that manipulate or query what should be the internal state of an object. If that is the case, move that logic to a method within the object.
Primitive obsession (Fowler): Using primitive data to express domain concepts. Inspect the parameters of methods and return types. More than two parameters are probably expressing something that could be expressed as an object. That object should reflect a domain concept and has to be defined with the name that a domain expert would use.
Command and Query separation (Meyer): A method should modify the system writing a new value (side-effect) or query data that is returned to the consumer, but never both.
Enforce immutability: Enforce as much as possible objects that cannot change after being created. Prevents from modifications by mistake.