It’s hard to make a better job than the official documentation does and it’s fair to wonder why one would make any effort to write something else. I have, of course, particular background and motivations. When I evaluate new technology, I always like to take a look at things in the context of a full-stack application, which is where I spend most of my time. It is usually in that space where I want to check if a technology is going to help me or not.
Crucially for beginners, Fulcro does not live isolated in the void. It is used within a medium, we still need our dependencies retrieved and managed and our code compiled, aspects where the newcomer must invest some time to make things work.
In this article, I try to draw the shortest and straightest line between zero and a full stack application. I didn’t know anything about web development in Clojure, so it was a bit hard for me to know what to expect. A comparison with Redux, a very popular choice for state management in React applications, and the analysis of their similarities and differences does result helpful, if you come from there.
This is a very introductory post, it offers a more relaxed and gentle introduction at the technology stopping briefly at some basics, an exercise that sometimes we cannot afford to do every day in the middle of our obligations. Even as a more experienced programmer, it is a good idea to make sure we dedicate some time to review the "why" of things and make some of our implicit knowledge, more explicit.
Creating an empty project
New projects created with the latest versions of Fulcro can use Deps, a dependency management and CLI tools where dependencies are expressed in a file that looks like this:
{:paths ["src/main" "resources"]
:deps {org.clojure/clojure {:mvn/version "1.10.1"}
com.fulcrologic/fulcro {:mvn/version "3.4.14"}
thheller/shadow-cljs {:mvn/version "2.15.2"}}
:aliases {:dev {:extra-paths ["src/dev"]
:extra-deps {org.clojure/clojurescript {:mvn/version "1.10.742"}
thheller/shadow-cljs {:mvn/version "2.15.2"}
binaryage/devtools {:mvn/version "0.9.10"}}}}}Different aliases can point to different dependencies, in this case only dev, but we can easily imagine configurations for testing or building a JAR file.
We are going to write the code of our application in Clojurescript, and it must be translated to Javascript so our browser can understand it. Shadow CLJS does that. Among other things, one can easily use NPM packages with it, an improvement from other options.
After completing the previous step, you should be able to have the application running and a root component loaded on the screen.
An initial comparison with Redux and some key points
This diagram captures a simplified architecture of Redux. In this example, it delivers the state changes notifications to React, as Fulcro does.
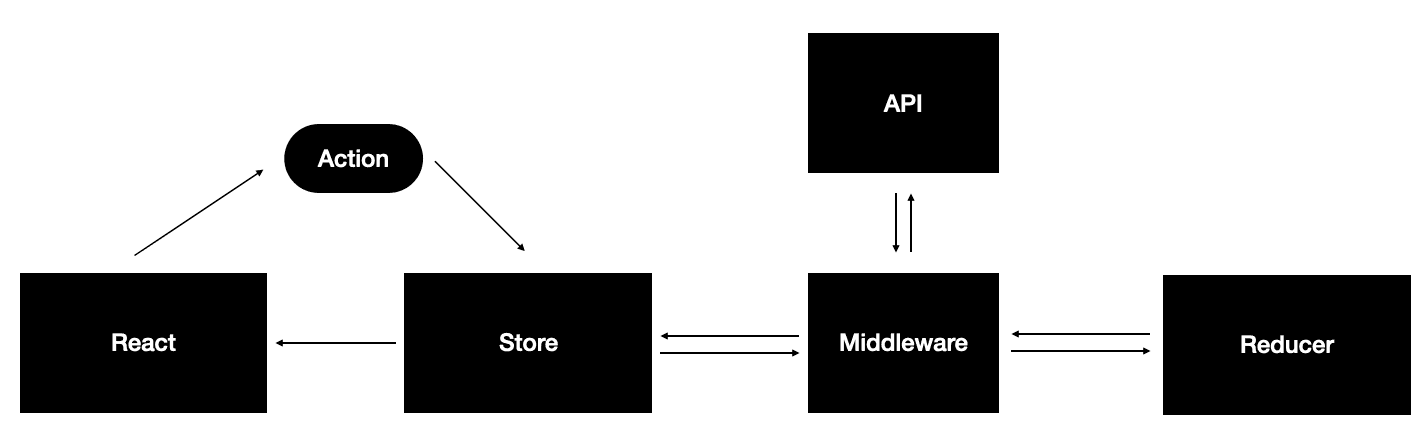
The solution provided by Fulcro is certainly similar:
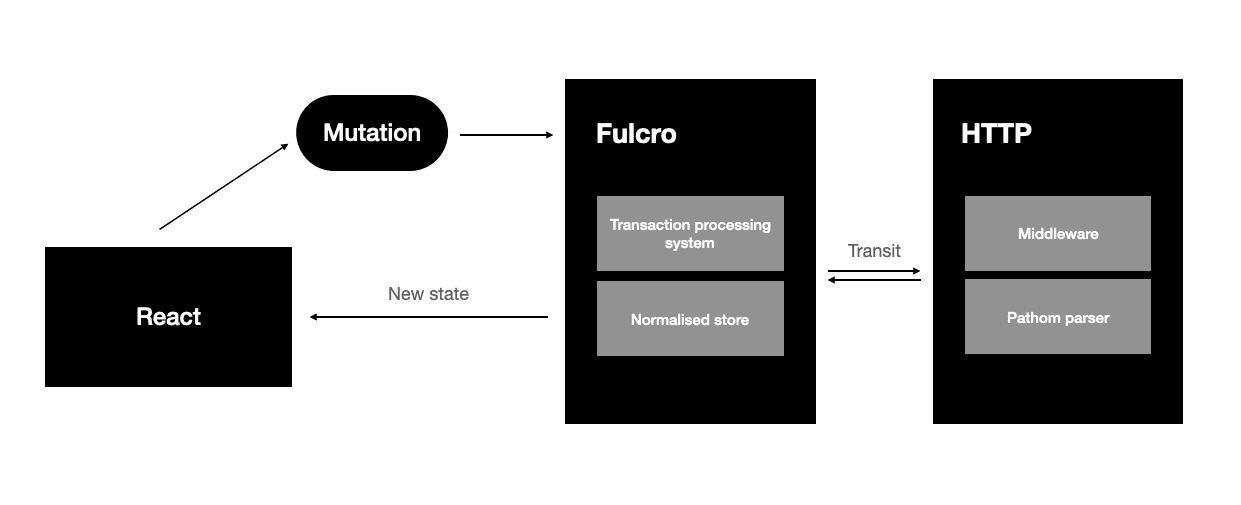
The view is also a function of the application state that is translated to elements in the DOM, and changes in the state are notified via a construct called mutation. However, Fulcro provides an integrated data-driven solution for interacting with servers, while one needs to handle all the details in a Redux application.
Part of what any library or framework that targets the frontend does is rendering, or in this case, translating a piece of more or less structured information, the state, to actual DOM elements that the browser can "paint" on the screen.
React uses a unidirectional data flow. The only reason why a view changes is because the state has changed, and the state is only changed via events. A different approach used by other frameworks is the bidirectional flow where views can manipulate the state and vice-versa through a synchronization mechanism provided by the framework.
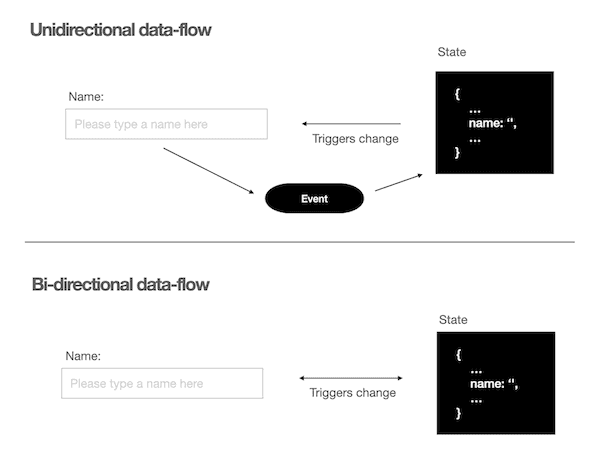
Proponents of the unidirectional data flow highlight how this approach makes systems conceptually easier to understand. Applied to our case, the unidirectional data flow means that for each change the entire state is given again the root component and gets disseminated to their children.
Consider this for a moment. For a small change that only affects a simple property rendered just in one component, we generate a new copy of the state with the property updated and give it to the root component that passes down the information until it reaches where it was needed. It may seem expensive from the point of view of performance. Fortunately, React works with the concept of a VirtualDOM. An in-memory representation of the DOM is used like cache, where differences between the new and the old state can be computed to update the DOM efficiently. Fulcro adds an algorithm on top of this to refresh only those components affected by the last mutation.
Mutations are similar to the handlers of Redux’s reducers, as given some event they take the state to produce a new version of it. Mutations are encoded in Clojure more like a request, they look like a call but are data. This enables serialization and putting in the wire so the same operation can be communicated locally and remotely.
(comp/transact! this [(please-do-this-for-me)])The client database (equivalent to the Redux store)
Fulcro uses a single client database. Redux allows, and even recommends, having different stores that reflect the shape of the application. Fulcro’s client database is also normalized and uses a graph structure (nodes and edges) to store entities and their relationships. Initially, they are both the same, a blank space in the memory ready to be filled up.
Normalization
Let’s take a look at this example of a quite typical screen for a mobile application that manages the upcoming flights and pilots schedules for an airline:
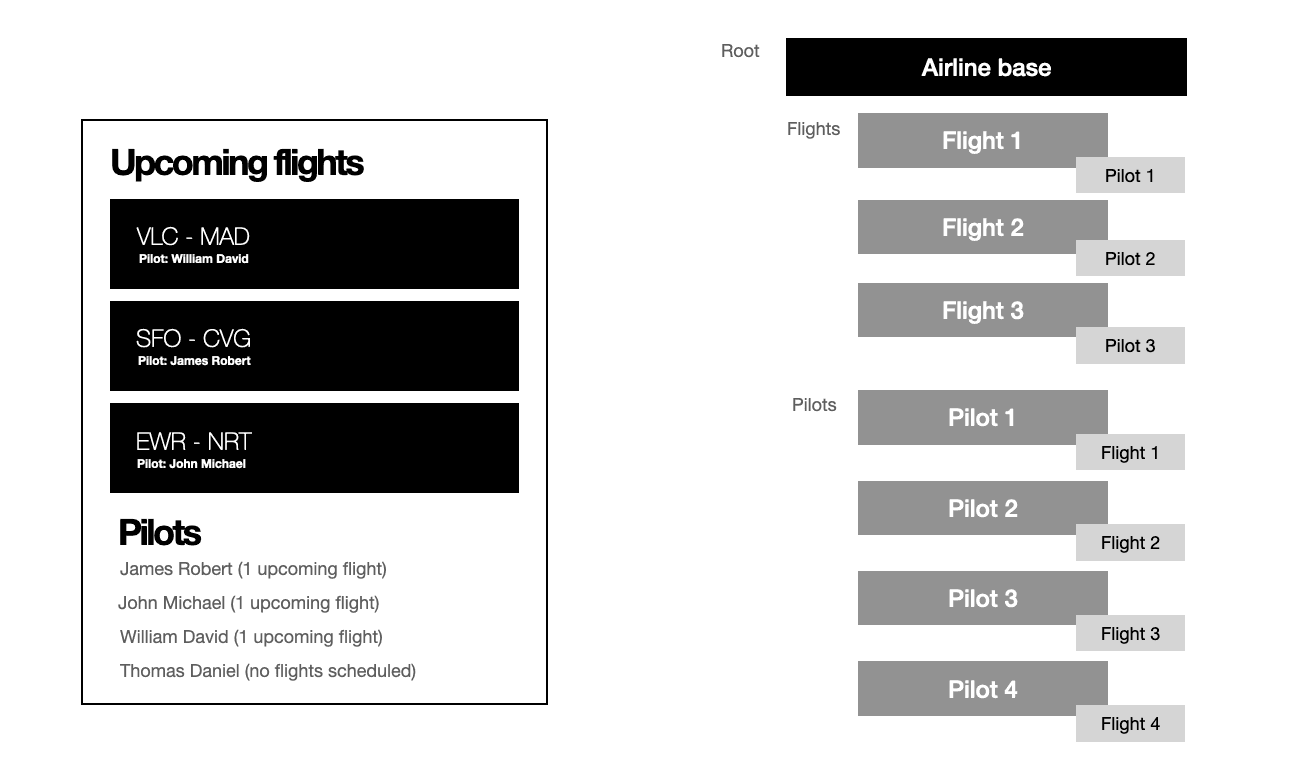
The structure looks like this: An airline base has upcoming flights and pilots. Flights can have assigned pilots or not, and the users again have a collection of flights themselves. The entities that form the UI are pretty interconnected between themselves, as it often happens in most applications, even more as they grow.
The information appears repeated. Whenever the state needs to be updated, if the pilot assigned for a flight changes for instance, that means finding the flight and updating the reference, and exploring the pilots collection to remove the flight from the original pilot and adding it to the new choice. The problem may seem trivial at this scale, but it really puts pressure on the development as applications and connections grow. So the question is, can we somehow express this graph in a concise way, without this duplication?.
Fulcro fixes this through normalization on the client-side. Items in the store are indexed by id and they only exist in one place as any reference to another element of our state will be expressed with an ident, a representation of objects that works like a pointer. It signals where the data is located without containing it:
[:flight/by-id 123]One just needs to decide what items will have a presence on the UI and how they interact with each other. Once this analysis is made, the information must follow this structure to be inserted in the store. There are some benefits that come from this:
-
Duplication does not exist in the data. Although we may have a UI element that appears on several places, the information that feeds the component is still coming from just one place. There is no need to find several occurrences of the same information disseminated several times on the state. Once the state is updated, all views get updated.
-
The store has a very predictable structure. This enables a lot of generalization and opens the potential to code reuse in our mutations. Properties are only two or three levels deep, the identifier of the resource, the id, and the property that needs change.
-
It also avoids different tastes and opinions on how the state needs to be structured specifically. Here the answer to that questions is already given.
The idents specified in the components help Fulcro to understand the identities of the elements present in the state and normalize them accordingly.
Graph implementation
The store is an immutable map where items are organised in “tables” and the relationships are expressed via pointers that are called idents. It could look something like:
{:pilots/by-id {1 {:pilot/name "James Robert" :pilot/flights [[:flight/by-id 2]]}
2 {:pilot/name "John Michael" :pilot/flights [[:flight/by-id 3]]}
3 {:pilot/name "William David" :pilot/flights [[:flight/by-id 1]]}
4 {:pilot/name "Thomas Daniel" :pilot/flights []}}
:flights/by-id {1 {:flight/from "VLC" :flight/to "MAD" :flight/pilot [:pilot/by-id 3]}
2 {:flight/from "SFO" :flight/to "CVG" :flight/pilot [:pilot/by-id 1]}
3 {:flight/from "EWR" :flight/to "NRT" :flight/pilot [:pilot/by-id 2]}}}In this example, we have three flights, with a connection to its pilot. Also pilots, are connected to their flights via a collection of idents pointing to flights.
The component and changing the state
Now that we have a basic understanding of the store and how it works, let’s write a very simple component that can write on the store the current date-time and print it on the screen. Components in Fulcro can express their interest in one specific part of the graph via a property called query.
For this example, we will write the date on a root key called :ui/date.
(defmutation set-date-time [params]
(action [{:keys [state]}]
(swap! state assoc :ui/date (:to params)))
(defsc Root [this {:ui/keys [date]}]
{:query [:ui/date]
:initial-state {:ui/date "Not set"}}
(dom/div
(dom/div (str date))
(dom/button {:onClick (fn [_e]
(comp/transact! this [(set-date-time {:to (.now js/Date)})]))} "Update date")))The root component states on :query that it needs to know about ui/date. It renders also a button that applies a transaction when clicked. The transaction applied, [(set-date-time)] can be seen as a request to the centralized transaction system. The component is just submitting a piece of data to the transactions system and knows nothing more than the name and the parameters.
The swap syntax can be a bit intimidating to newcomers. The overload seen here:
(swap! state assoc :ui/date (.now js/Date))Changes the state atom calling the function assoc with the state also and passing the rest of the parameters as arguments to it. An isolated call to assoc looks like this:
(assoc state :ui/date (.now js/Date))One different way depicted in the Fulcro docs is creating an extra function and pass it the parameters of the mutation, like this:
(defn set-date-time* [state params]
(assoc state :ui/date (:to params)))
(defmutation set-date-time [params]
(action [{:keys [state]}]
(swap! state set-date-time* params)))Now the mutation purely acts as a bridge transferring the request to the new function, that takes the state and the params. Having this new function can actually help beginners a bit to forget about swap! syntax. Also, it is easy to see how it can be trivially tested, without the need of any special tooling or calling Fulcro. You could very easily prepare different versions of the state and combination of the params, and verify the results. These functions could, for example, be taken to a different namespace where we would actively avoid source code dependencies over the framework. The file would not require any of the Fulcro namespaces.
Adding a server. Going full-stack.
We mentioned before how mutations look like calls but they are actual data. If the mutation has a remote part, Fulcro puts it in the wire and sends it to the backend saving us dealing with all the low-level details involved in operating with the endpoint.
(defmutation add-person [params]
(action [env] ...)
(remote [env] ...)
(rest [env] ...)
(ok-action [env] ...)
(error-action [env] ...))Like in many other occasions, we need a server listening and logic able to process the request. In this example, we use an HTTP server. We have HTTP as the application layer protocol that will coordinate the communication between client and server, but still the data needs to be exchanged using in some data format. Fulcro uses Transit, a format that claims less verbosity and better extensibility compared to other options.
Adding a remote
We need to let Fulcro know that the application will be operating with a backend. This is quite easy, we just need to add some data to the configuration map passed down to Fulcro-app and set that we will be using an HTTP remote.
(defonce app (app/fulcro-app {:remotes {:remote (net/fulcro-http-remote {})}}))The parser, explained
Parsing queries at Fulcro, and in other systems that use the same ideas are based on a couple of foundational facts:
-
User interfaces behave like graphs, where data is interconnected and items have relationships with others.
-
To retrieve data we favor a declarative approach. It is better to express what one needs as opposed to be responsible for the procedural description of how it is going to be retrieved specifically. To put a more precise example, if a view needs to retrieve data from four different locations, it is simpler to just declare the data that the view needs and ask something else to resolve it, than to have to coordinate the call to four different REST endpoints.
In this space and to put an example of a different technology, GraphQL is a declarative query language made originally at Facebook as a replacement for REST APIs developed as a response to problems they found working at their scale. As mentioned, GraphQL is a language, so it’s agnostic to how information is stored. It just describes what is needed. Any solution using GraphQL needs a parser that understands the queries and returns the information requested.
In our case, we will be using Pathom, a library that helps you to write graph query processing parsers for the query notation used by the EDN query language (EQL). The client side can express the data that it needs and then submit the request for the load.
We reflected before on how it is an advantage to be able to declare exactly what data is needed. The client must decide entirely how this request will look, and in Fulcro this is constructed from the components, taking their query properties and building the EQL request from them.
(defsc Flight [this {:flight/keys [from to]}]
{:query [:flight/id :flight/from :flight/to]
:ident [:flights/by-id :flight/id]}
(dom/div
(dom/div from)
(dom/div to)))
(def ui-flight (comp/factory Flight {:keyfn :flight/id}))
(defsc FlightsList [this props]
{:query [{:page/flights ['*]}]
:ident (fn [] [:page/flights-list :singleton])}
(dom/div
(map #(ui-flight %) props)))
(def ui-flights-list (comp/factory FlightsList))
(defsc Root [this {:page/keys [flights]}]
{:query [{:page/flights ['*]}]}
(ui-flights-list flights))First, we have a component called Flight that we will use to render a flight. Whenever the data from the flights comes back from the server, Fulcro will need to know how to normalize it. This requires being able to detect the identifier of elements so it can act as the key it will be used to index it. This is made via the ident property of the component. For this ident [:flights/by-id :flight/id] and this flight:
{:flight/id 1 :flight/from "VLC" :flight/to "MAD"}Fulcro knows that these objects must be put in a "table" called "flights/by-id" and store it a map where the identifier "1" will be the key.
The query key makes components capable of expressing the part of the graph they are interested in. Finally, the load statement:
(defn ^:export init
...
(df/load! app :page/flights Flight)
...
)Three parameters need to be given, the Fulcro app instance, the root key that will be loaded, :page/flights and the component from which it will get the query. This code triggers this query:
[{:page/flights [:flight/id :flight/from :flight/to]}]
Now we need to code how the parser will fulfill it, returning a data structure that matches completely the one specified by the client. This is a minimal implementation of a parser that returns valid data:
(def flights-sample
[{:flight/id 1 :flight/from "VLC" :flight/to "MAD"}
{:flight/id 2 :flight/from "SFO" :flight/to "CVG"}
{:flight/id 3 :flight/from "EWR" :flight/to "NRT"}])
(pc/defresolver flights
[env _]
{::pc/output [:page/flights [:flight/id :flight/from :flight/to]]}
{:page/flights flights-sample})
(def resolvers [flights])The resolver declares also the type of data that it can return. In this case, the output of the resolver will be one key, page/flights and a list of elements with an id, source and destination. When the request comes, Pathom can match the key selected with the one it has specified in the output. The Flights resolver is therefore executed.
Now, we should see the information on the screen. The root component composes its query with the one specified in the Flight component. We have previously specified the ident of a flight in the component, which is also part of the load statement. When the result arrives from the server, Fulcro can search in the returned elements for the ident, and store them normalized.
The EQL query language is very powerful, and of course one can express far more complicated queries than the one we just did. For example, a flight has usually a pilot associated. Let's change the frontend accordingly:
(defsc Pilot [this {:pilot/keys [id name]}]
{:query [:pilot/id :pilot/name]
:ident [:pilot/by-id :pilot/id]}
(dom/div
(dom/div name)))
(def ui-pilot (comp/factory Pilot {:keyfn :pilot/id}))
(defsc Flight [this {:flight/keys [id from to pilot]}]
{:query [:flight/id :flight/from :flight/to {:flight/pilot (comp/get-query Pilot)}]
:ident [:flights/by-id :flight/id]}
(dom/div
(dom/div from)
(dom/div to)
(ui-pilot pilot)))The flight component adds to the query a new component, a JOIN with the pilot:
[:flight/id :flight/from :flight/to {:flight/pilot (comp/get-query Pilot)}]The pilot is another entity that is normalized too. The properties to be retrieved from the client database, are specified in the Pilot component, which query can be composed with the one seen in Flight. When the load is made, this is what the server receives:
[{:page/flights
[:flight/id
:flight/from
:flight/to
{:flight/pilot [:pilot/id :pilot/name]}]}]This resolver is a bit different. The first one did not have an input as we were trying to resolve a root query but now we need to get the pilot associated in the context of a flight. The resolver looks like this:
(pc/defresolver pilot
[env {:flight/keys [id]}]
{::pc/input #{:flight/id}
::pc/output [:flight/pilot [:pilot/id :pilot/name]]}
(find-pilot-for-flight id)